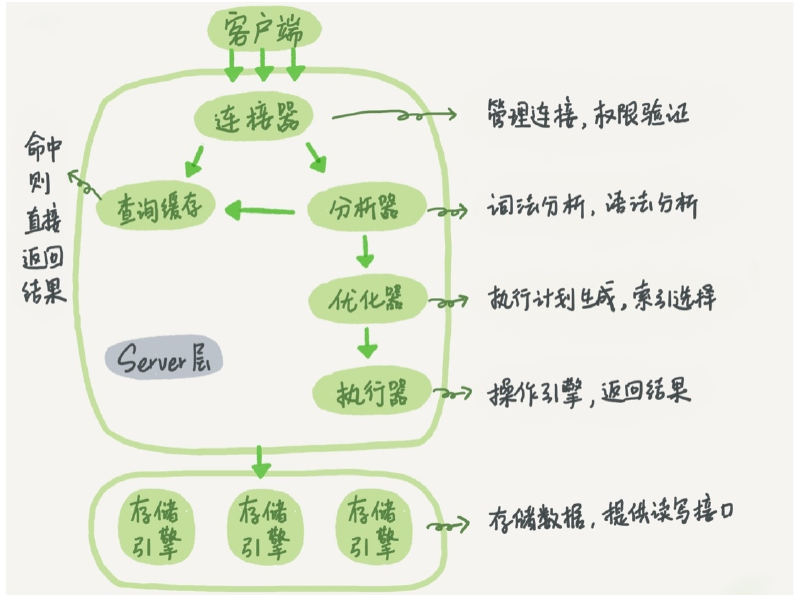
查询过程
查询缓存
Mysql 拿到一个查询请求后,会先到查询缓存看是否执行过该语句。缓存可能会以 key-value 对形式直接缓存在内存,如果能直接在缓存中找到结果,就直接返回 value 给客户端,否则,就继续后面的执行阶段。执行完成后,执行结果被存入查询缓存。
但是查询缓存的失效非常频繁,只要对一个表有更新,这个表上所有查询缓存都会被清空。从 mysql8.0 版本,查询缓存的功能被删除了。
日志系统
redolog
WAL 技术全称是 Write-Ahead Logging 先写日志,再写磁盘,当有一条记录需要更新的时候,innodb 会把记录写到 redo log,并更新内存,并在适当的时候,将这个操作记录更新到磁盘。redolog 的大小是固定的,写到末尾又会回到开头覆写。
因为 redolog,innodb 可以保证数据库异常重启后,之前提交的记录不会丢失,称为 crash-safe。
binlog
redolog 是 innodb 特有的 log,而 server 层也有自己的日志,称为 binlog(归档日志)
redolog 是物理日志,记录在某个数据页做了什么修改,binlog 是逻辑日志,记录的是语句的原始逻辑
binlog 采用追加写,写到一定大写后会创建新的 binlog,不会覆盖之前的日志
两阶段提交
浅色表示在 innoDB 内部执行,深色表示在执行器中执行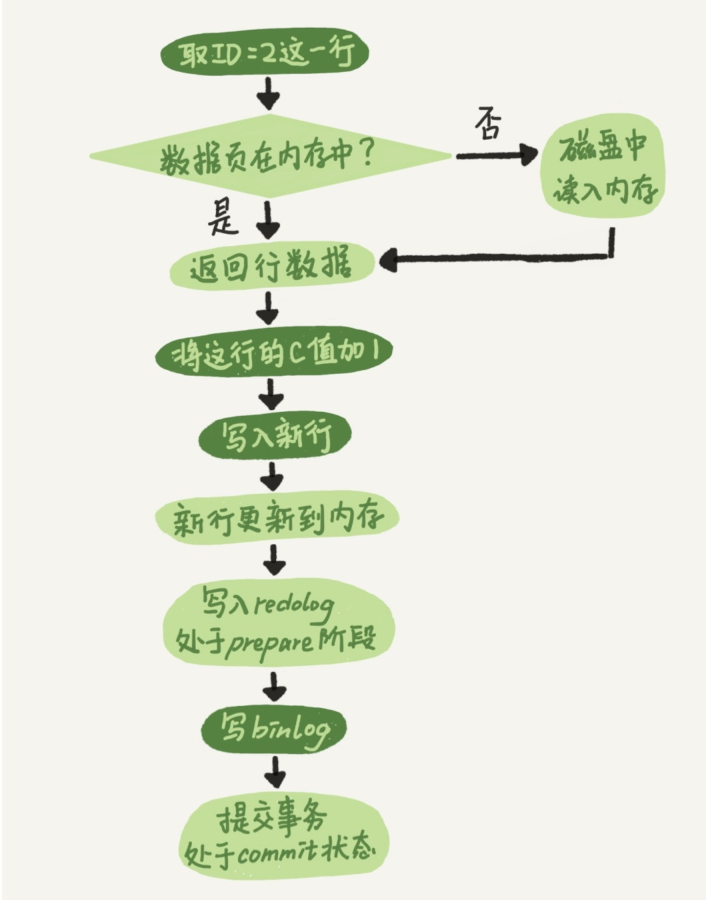
redolog 的写入拆分成 parpare 和 commit 两步,保证两个日志逻辑上的一致,这给了 binlog 和 redolog 一个同时说 ok 的机会
崩溃恢复原则
redo log 和 binlog 有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
- 如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
- 如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
- binlog 无记录,回滚事务
- binlog 有记录,提交事务。
其他
set innodb_flush_log_at_trx_commit = 1 将每次事务都持久化到磁盘
set sync_binlog = 1 将每次事务的 binlog 都持久化到磁盘
事务隔离
读未提交,一个事务还没提交时,它做的变更就能被别的事务看到
读提交,一个事务提交之后,他做的变更才会被其他事务看到
可重复读是,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一样的,未提交的变更对其他事务是不可见的
串行化,对于同一行记录,写会加写锁,读会加读锁,当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成后才能继续执行
配置方式 将启动参数 transaction_isolation 的值设置成 READ-COMMITTED,可以用 show variables 查看当期数值
数据库内会创建一个视图,访问的时候以视图的逻辑结果为准。在可重复读隔离级别下,这个视图是在事务启动的时候创建的,整个事务存在期间都用这个事务。在读提交级别下,这个视图是在每个 sql 语句开始执行的时候创建的。读未提交没有视图概念,串行化直接用加锁的方式避免并行访问。
事务隔离的实现
可重复读 每条记录在更新的时候都会同时记录一条回滚操作,记录上的最新值,通过回滚操作,可以得到前一个状态的值
不同时刻启动的事务会有不同的 read-view,同一个记录的值分别是 1,2,3,4,同一个记录在系统中可以存在多个版本,这是数据库的多版本并发控制 mvcc。对于 read-view A,要得到更新后的值,就必须将当前数值依次执行所有回滚操作
回滚日志会一直保留到没有比这个更早的 read-view 的时候,因此尽量不要使用长事务
事务的启动方式
显式启动事务 begin 或 start transaction 提交使用 commit 回滚使用 rollback
set autocommit=0 会将线程的自动提交关掉,这意味着事务不会自动提交,知道主动执行 commit 或者 rollback 或者断开连接,建议总是设置 autocommit 为 1
可以在 informatino_schema 库的 innodb_trx 表中查询长事务
索引
- 三种数据结构
- 哈希表 优点是增加新的 user 时速度很快,只需要往后追加,但缺点是,因为不是有序的,哈希索引做区间查询速度很慢
- 有序数组 在等值查询和范围查询场景的性能非常优秀,但是需要插入的时候成本太高,只适用于静态存储引擎
- 搜索树 目前数据库中使用的是 N 叉数
innodb 的索引模型
- innodb 中,表都是根据主键顺序以索引的形式存放的,这种方式称为索引组织表,使用 B+树索引模型,所有数据存储在 B+树中。
- 主键索引的叶子节点存的是整行数据,在 innodb 中,主键索引也被称为聚簇索引,非主键索引的叶子节点的内容是主键的数值,非主键索引也被称为二级索引
- 使用二级索引查表需要先找到主键的值,再在主键的索引书搜索一次,这个过程称为回表
索引维护
- 主键索引树需要保持树的有序性,自增主键的插入数据模式的耗时很低,而有业务逻辑的字段作主键,往往不容易保证有序插入,这样写数据的成本相对较高
- 而且从空间角度,使用 int 型作为主键,占用的空间也较小,主键索引越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小
- 直接用业务字段作主键
- 只有一个索引
- 该索引必须是唯一索引
覆盖索引
如果在某个查询里面,索引 k 已经覆盖了我们的查询需求,我们称其为覆盖索引。覆盖索引可以减少树的搜索次数,显著提升查询性能
最左索引
- 不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以使联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
下推优化
mysql5.6 之后,可以在索引遍历的过程中,对索引包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表的次数
重建索引
重建主键索引会将整个表重建
- 普通索引与唯一索引的性能差距
对于普通索引,查找到满足条件的第一条记录后,还需要继续查找知道碰到第一个不满足条件的记录,对于唯一索引,由于定义了唯一性,查找到第一个满足条件的记录后就会停止继续检索,这带来的性能差距呢是微乎其微,innodb 是按照页读写的,当找到记录的时候,他所在的数据页也都在内存中,因此下一次查找的消耗很低 - change buffer
当需要更新一个数据页时,如果数据页在内存中就直接更新,如果不再,在不影响数据一致性的前提下,innodb 会将更新操作缓存在 changer buffer 中,当下一次查询需要访问这个页面的时候,将数据读入内存,然后执行 change buffer 中与这个页有关的操作。很像操作系统中的页面交换。 - 将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 purge,除了访问这个数据页会触发 purge,还有后台线程会定期 purge,在数据库正常关闭的过程中,也会执行 purge
- 对于唯一索引,所有更新操作都先判断这个操作是否违反唯一约数,要将数据页读入内存才能判断,没必要使用 change buffer 实际上只有普通索引可以使用
- change buffer 用的是 buffer pool 里的内存,可通过 innodb_change_buffer_max_size 来动态设置
- 对于写多读少的业务,比较适合使用 change buffer,如果业务写入之后立即查询,由于会频繁触发 purge 过程,增加了 change buffer 的维护代价,反而起到了副作用
mysql 选择了错误的索引
- 可以使用 force index 强制选取使用的索引