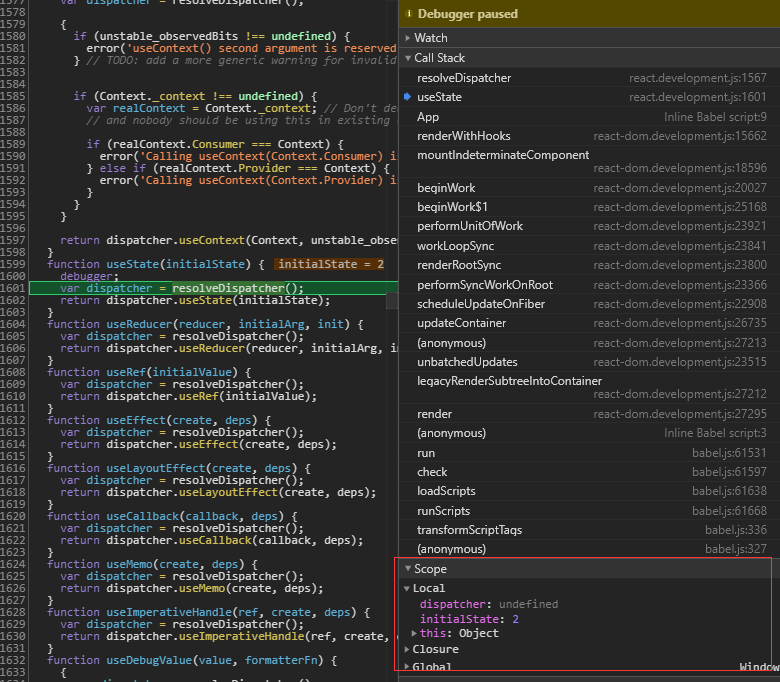
Selectors can compute derived data, allowing Redux to store the minimal possible state. 选择器可以计算派生数据,从而允许 Redux 存储尽可能少的状态。 Selectors are efficient. A selector is not recomputed unless one of its arguments changes. 选择器是高效的。除非选择器的一个参数发生更改,否则不会重新计算选择器。 Selectors are composable. They can be used as input to other selectors. 选择器是可组合。它们可以用作其他选择器的输入。
const memoizedResultFunc = memoize(function () { recomputations++; // apply arguments instead of spreading for performance. return resultFunc.apply(null, arguments); }, ...memoizeOptions);
// If a selector is called with the exact same arguments we don't need to traverse our dependencies again. const selector = memoize(function () { const params = []; const length = dependencies.length;
for (let i = 0; i < length; i++) { // apply arguments instead of spreading and mutate a local list of params for performance. params.push(dependencies[i].apply(null, arguments)); }
// apply arguments instead of spreading for performance. return memoizedResultFunc.apply(null, params); });
exportfunctiondefaultMemoize(func, equalityCheck = defaultEqualityCheck) { let lastArgs = null; let lastResult = null; // we reference arguments instead of spreading them for performance reasons returnfunction () { if (!areArgumentsShallowlyEqual(equalityCheck, lastArgs, arguments)) { // apply arguments instead of spreading for performance. lastResult = func.apply(null, arguments); }
publicclassMain{ publicstaticvoidmain(String[] args){ int i = 2147483647; int i2 = -2147483648; int i3 = 2_000_000_000; // 加下划线更容易识别 int i4 = 0xff0000; // 十六进制表示的16711680 int i5 = 0b1000000000; // 二进制表示的512 long l = 9000000000000000000L; // long型的结尾需要加L } }
String s = """ SELECT * FROM users WHERE id > 100 ORDER BY name DESC """;
由于多行字符串是作为预览特性(Preview Language Features)实现的,编译的时候,我们还需要给编译器加上参数:
1
javac --source 14 --enable-preview Main.java
常量
定义变量的时候,如果加上 final 修饰符,这个变量就变成了常量:
var 关键字
1
var sb = new StringBuilder();
编译器会自动推导类型
数组
自定义排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
publicclassBasic{ publicstaticvoidmain(String[] args){ // 不能使用基本类型,而要使用它们对应的类 Integer[] ns = {1, 2, 3, 4, 5}; for (int n : ns) { System.out.println(n); } Arrays.sort(ns, new Comparator<Integer>() { @Override publicintcompare(Integer a, Integer b){ return b - a; } }); System.out.println(Arrays.toString(ns)); } }
OOP
传参
引用类型传的是引用,会修改传递的应用类型数据本身
向下转型
1 2 3 4
Person p1 = new Student(); // upcasting, ok Person p2 = new Person(); Student s1 = (Student) p1; // ok Student s2 = (Student) p2; // runtime error! ClassCastException!
这个 Class 实例是 JVM 内部创建的,如果我们查看 JDK 源码,可以发现 Class 类的构造方法是 private,只有 JVM 能创建 Class 实例,我们自己的 Java 程序是无法创建 Class 实例的。 所以,JVM 持有的每个 Class 实例都指向一个数据类型(class 或 interface):
一个 Class 实例包含了该 class 的所有完整信息。由于 JVM 为每个加载的 class 创建了对应的 Class 实例,并在实例中保存了该 class 的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等,因此,如果获取了某个 Class 实例,我们就可以通过这个 Class 实例获取到该实例对应的 class 的所有信息。
这种通过 Class 实例获取 class 信息的方法称为反射(Reflection)。
获取一个 class 的 Class 实例有三个方法 方法一:直接通过一个 class 的静态变量 class 获取:
1
Class cls = String.class;
方法二:如果我们有一个实例变量,可以通过该实例变量提供的 getClass()方法获取:
1 2
String s = "Hello"; Class cls = s.getClass();
方法三:如果知道一个 class 的完整类名,可以通过静态方法 Class.forName()获取:
1
Class cls = Class.forName("java.lang.String");
因为 Class 实例在 JVM 中是唯一的,所以,上述方法获取的 Class 实例是同一个实例。可以用==比较两个 Class 实例:
1 2 3 4 5 6 7
Integer n = new Integer(123);
boolean b1 = n instanceof Integer; // true,因为n是Integer类型 boolean b2 = n instanceof Number; // true,因为n是Number类型的子类
用 instanceof 不但匹配指定类型,还匹配指定类型的子类。而用==判断 class 实例可以精确地判断数据类型,但不能作子类型比较。 通常情况下,我们应该用 instanceof 判断数据类型,因为面向抽象编程的时候,我们不关心具体的子类型。只有在需要精确判断一个类型是不是某个 class 的时候,我们才使用==判断 class 实例。
访问字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
publicclassTest{
publicstaticvoidmain(String[] args)throws Exception { Object p = new Person("Xiao Ming"); Class c = p.getClass(); Field f = c.getDeclaredField("name"); Object value = f.get(p); System.out.println(value); } }
publicclassMain{ publicstaticvoidmain(String[] args)throws Exception { var add = new AddThread(); var dec = new DecThread(); add.start(); dec.start(); add.join(); dec.join(); System.out.println(Counter.count); } }
sed -i 's/http:\/\/updates.jenkins-ci.org\/download/https:\/\/mirrors.tuna.tsinghua.edu.cn\/jenkins/g' default.json && sed -i 's/http:\/\/www.google.com/https:\/\/www.baidu.com/g' default.json
public getId(): number { returnthis.id; } public getCreateTime(): Date { returnthis.createTime; } public getBalance(): number { returnthis.balance; } public getBalanceLastModifiedTime(): Date { returnthis.balanceLastModifiedTime; } public increaseBalance(amount: number): void { this.balance += amount; this.balanceLastModifiedTime = newDate(); } public decreaseBalance(amount: number): void { this.balance -= amount; this.balanceLastModifiedTime = newDate(); } }
对于封装这个特性,需要编程语言本身提供访问权限控制的语法机制来支持。
之所以这样设计,是因为从业务的角度来说,id、createTime 在创建钱包的时候就确定好了,之后不应该再被改动,所有只提供 get 方法,这两个属性的初始化设置,对于调用者也是透明的,所以不提供用构造参数的方式进行外部赋值。
alter profile 概要文件名 limit sessions_per_user 20 failed_login_attemps 3;
删除:
1
drop profile 概要文件名;
说明: 一个用户所使用的概要文件被删除,则此用户使用默认的概要文件。 使某个用户使用某个用户配置文件 aler user 用户名 profile 概要文件名; 要使上面的限制生效,需要修改初始化参数 resource_limit alter system set resource_limit=true;(11g)
当你使用 component 时,router 使用 React.CreateElement 根据传递的 component 创建一个新的 React element 。这意味着如果你提供了一个内联的函数给 component 属性,你会在每次 render 的时候都创建这个组件,这会导致旧组件的 unmount 和 新组建的 mount
其背后的原理在于,react 在比较组件状态以便决定如何更新 dom 节点时,首先要比较组件的 type 和 key。在使用<Route component={() => (<Bar idx={this.state.idx}/>)}/>时,由于调用了 React.createElement,组件的 type 不是 Bar 这个类,而是一个匿名函数。App 组件每次 render 时都生成一个新的匿名函数,导致生成的组件的 type 总是不相同,所以会产生重复的 unmounting 和 mounting。
classCompextendsReact.Component{ componentDidUpdate(prevProps) { // will be true const locationChanged = this.props.location !== prevProps.location;
// INCORRECT, will *always* be false because history is mutable. const locationChanged = this.props.history.location !== prevProps.history.location; } }
// only consider an event active if its event id is an odd number const eventID = parseInt(match.params.eventID); return !isNaN(eventID) && eventID % 2 === 1; }} > Event 123 </NavLink>
// also works when nested inside other reactive objects const bar = reactive({ foo }); console.log(isReactive(bar.foo)); // false
shallowReactive
创建一个只追踪它自己的属性的响应性的对象(不会深度追踪嵌套的对象)
1 2 3 4 5 6 7 8 9 10 11 12
const state = shallowReactive({ foo: 1, nested: { bar: 2, }, });
// mutating state's own properties is reactive state.foo++; // ...but does not convert nested objects isReactive(state.nested); // false state.nested.bar++; // non-reactive
shallowReadonly
创建一个只使得它自己的属性是只读的对象(不会深度使嵌套的对象只读)
1 2 3 4 5 6 7 8 9 10 11 12
const state = shallowReadonly({ foo: 1, nested: { bar: 2, }, });
// mutating state's own properties will fail state.foo++; // ...but works on nested objects isReadonly(state.nested); // false state.nested.bar++; // works
shallowRef
创建一个 ref,只使得它自身的 value 属性是响应性的
1 2 3 4 5
const foo = shallowRef({}); // mutating the ref's value is reactive foo.value = {}; // but the value will not be converted. isReactive(foo.value); // false
其中 S 取值为 0 或 1,用来决定数 X 的符号;M 是一个二进制定点小数,称为数 X 的尾数(mantissa),E 是一个二进制定点整数,称为数 X 的阶或指数;R 是基数(radix、base)。在基数 R 一定的情况下,尾数 M 的位数反映数 X 的有效位数,它决定了数的表示精度,有效位数越多,表示精度就越高,阶 E 的位数决定数 X 的表示范围,阶 E 的位数决定数 X 的表示范围;阶 E 的值确定了小数点的位置。
从浮点数的形式来看,绝对值最小的非零数是如下形式的数:$0.0···01R^{-11···1}$,而绝对值最大的数的形式应为 $0.11···1R^{11···1}$,所以假设 m 和 n 分别表示阶和尾数的位数,基数为 2,则浮点数 X 的绝对值的范围为: