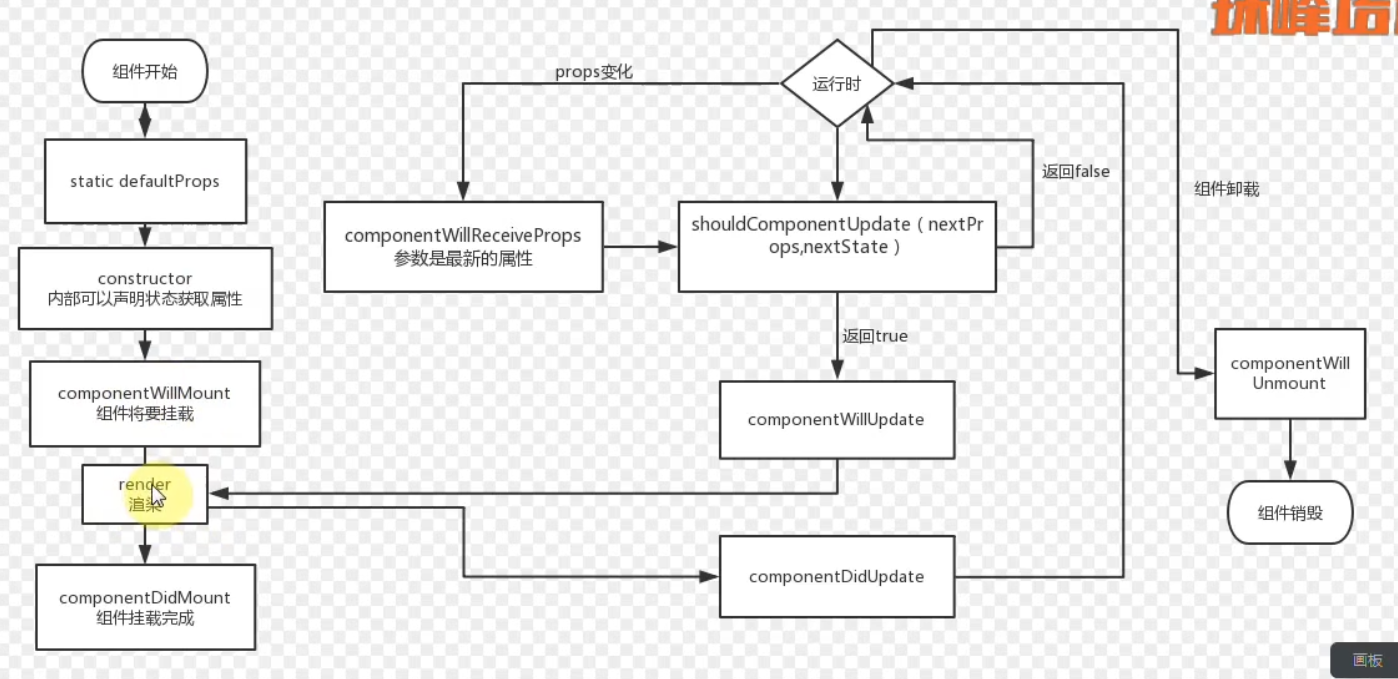
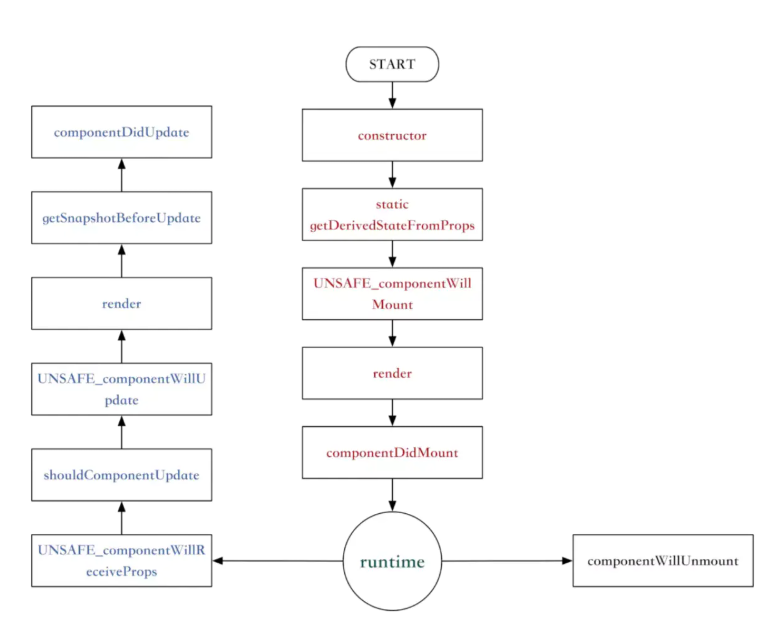
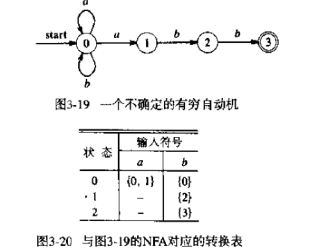
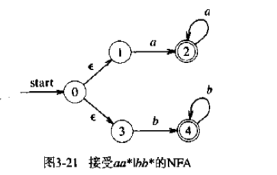
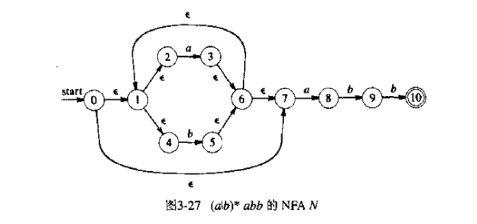
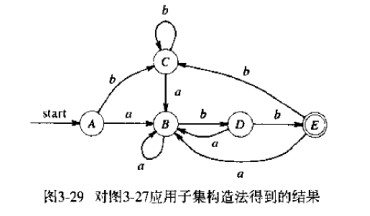
asyncfunctionread(){ let template = await readFile('./template.txt) let data = await readFile('./data.txt') return template + data } // 等同于 return read(){ return co(function*(){ let template = yield readFile('./template') let data = yield readFile('./data') return template + data }) }
// 根据 then 的传入处理函数 决定 then 返回的 promise 的状态 functionresolvePromise(promise2, x, resolve, reject) { if (x === promise2) { return reject(newTypeError("Circular reference")); } let called = false; if (x !== null && (typeof x === "object" || typeof x === "function")) { try { let then = x.then; if (typeof then === "function") { then.call( x, function (y) { if (called) return; called = true; resolvePromise(promise2, y, resolve, reject); }, function (err) { if (called) return; called = true; reject(err); } ); } else { if (called) return; called = true; resolve(x); } } catch (err) { if (called) return; called = true; reject(err); } } else { resolve(x); } }
Promise.prototype.catch = function (onRejected) { returnthis.then(null, onRejected); };
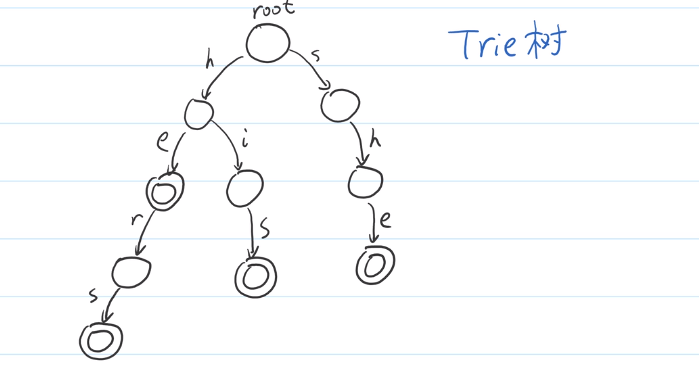
#include<bits/stdc++.h> usingnamespace std; constint maxn = 1e4 + 7; structaho { int size; structnode { int next[26]; int fail, cnt; node() { memset(next, 0, sizeof(next)); fail = cnt = 0; } } treeNode[maxn]; queue<int> q; voidinit() { while (!q.empty()) { q.pop(); } for (int i = 0; i < maxn; ++i) { memset(treeNode[i].next, 0, sizeof(treeNode[i].next)); treeNode[i].fail = treeNode[i].cnt = 0; } size = 0; } voidinsert(string s) { int cur = 0; for (int i = 0; i < s.length(); ++i) { int num = s[i] - 'a'; if (!treeNode[cur].next[num]) { treeNode[cur].next[num] = ++size; } cur = treeNode[cur].next[num]; } treeNode[cur].cnt++; }
voidbuild() { treeNode[0].fail = -1; queue<int> q; q.push(0); while (!q.empty()) { int top = q.front(); q.pop(); for (int i = 0; i < 26; ++i) { if (treeNode[top].next[i]) { q.push(treeNode[top].next[i]); if (top == 0) { treeNode[treeNode[top].next[i]].fail = 0; } else {
int v = treeNode[top].fail; while (v != -1) {
if (treeNode[v].next[i]) { treeNode[treeNode[top].next[i]].fail = treeNode[v].next[i]; break; } else { v = treeNode[v].fail; } } if (v == -1) { treeNode[treeNode[top].next[i]].fail = 0; } } } } } }
intgetNow(int cur) { int ret = 0; while (cur != -1) { ret += treeNode[cur].cnt; treeNode[cur].cnt = 0; cur = treeNode[cur].fail; } return ret; }
intfind(string target) { int res = 0; int pos = 0, cur = 0; while (pos < target.length()) { if (treeNode[cur].cnt) { res += getNow(cur); } int num = target[pos] - 'a'; if (cur == -1) { ++pos; cur = 0; } elseif (treeNode[cur].next[num]) { ++pos; cur = treeNode[cur].next[num]; } else { cur = treeNode[cur].fail; } } if (treeNode[cur].cnt) { res += getNow(cur); } return res; } // 用来检查构建的字典树和fail指针的指向 voidcheck() { int cur = 0; structpair { int v; string word; pair(int v, string word) : v(v), word(word){}; }; queue<pair> q; q.push(pair(0, "")); while (!q.empty()) { pair top = q.front(); q.pop(); for (int i = 0; i < 26; ++i) { if (treeNode[top.v].next[i]) {
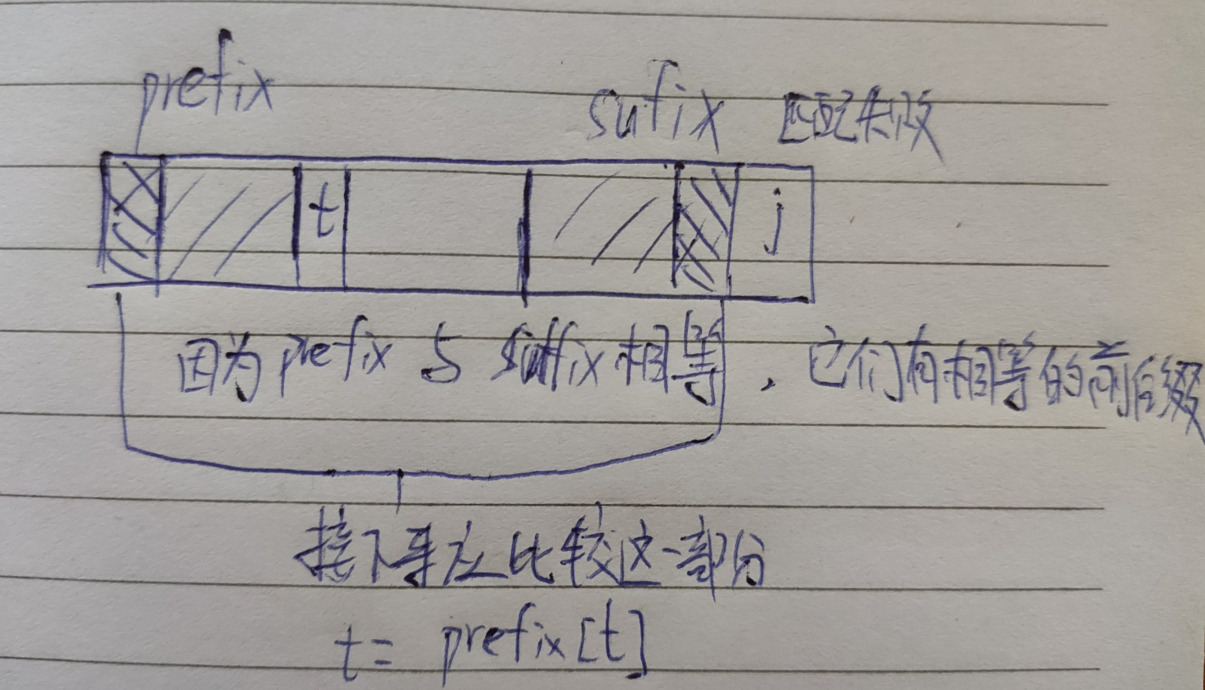
t = presuf[0] = -1 m = sp.length() while j < m-1 // 当前位置前后缀匹配,更新 presuf 数组 if t < 0 || sp[j] == sp[t] presuf[++j] = ++ t // 当前不匹配,则应该缩小前缀的范围 else t = presuf[t];
匹配流程
1 2 3 4 5 6 7 8 9 10 11
i = 0 j = 0 m = st.length() while j < m if i < 0 || sp[i] == st[i] ++i,++j if i == sp.length() // 得到结果 else // 这一步也很好理解,和构造过程是一样 i = presuf[i]
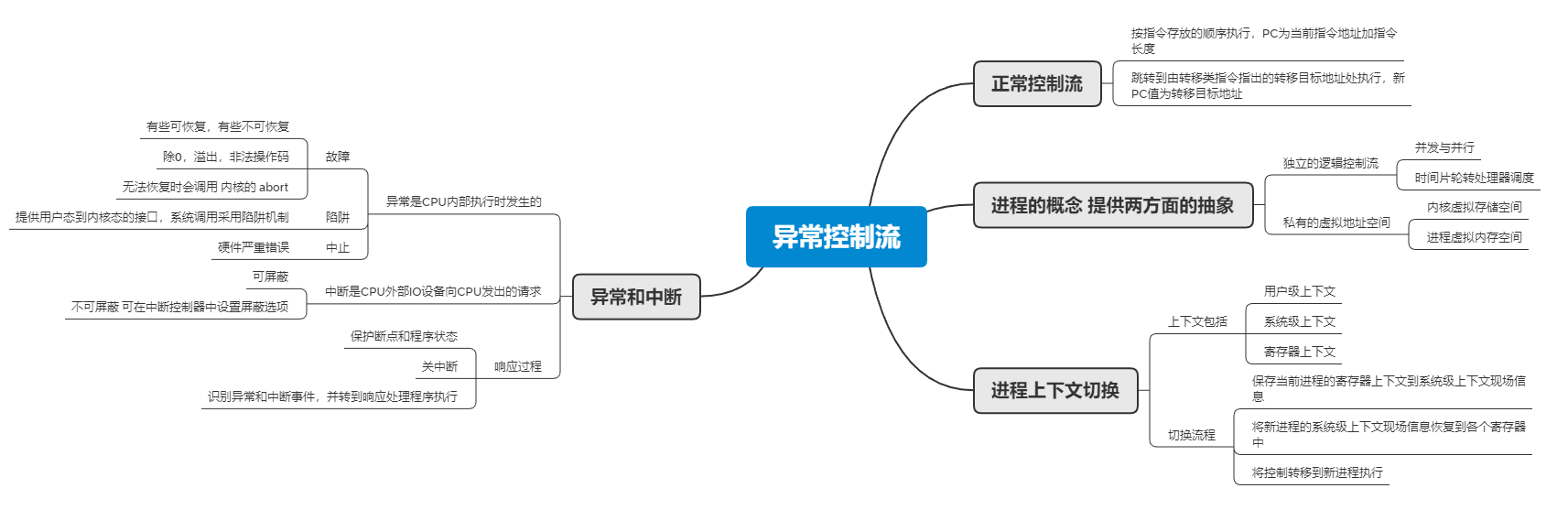
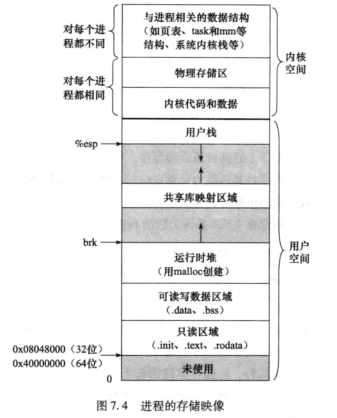
除了时间片到,当前进程的执行被新进程打断,还有用户按下 CTRL+C,当前执行执行中发生了不能使指令执行的意外事件,IO 设备完成了系统交给的任务需要进一步处理,这些特殊事件统称为异常或者中断。 当发生异常或者终端,正在执行进程的逻辑控制流被打断,CPU 转到具体的特殊处理事件的内核程序去执行。他与上下文切换有一个明显的不同:上下文切换后 CPU 执行另一个用户进程,但是,中断或异常处理程序执行的代码不是一个进程,而是一个内核控制路径,它代表异常或终端发生时正在运行的当前进程在内核态执行的一个独立的指令序列。作为一个内核控制路径,他比进程更轻,其上下文信息比一个进程的上下文信息少得多。
基本概念
异常是在 CPU 内部执行时发生的,中断是 CPU 外部的 IO 设备向 CPU 发出的请求,通常称异常为内部异常,而称中断为外部中断。
大致处理流程如下:当 CPU 在执行当前程序或任务的第 i 条指令时检测到一个异常事件,或者在执行第 i 条指令后发现有一个中断请求信息,CPU 会打断当前用户进程,然后转到相应的异常或中断处理程序去执行。如果该处理程序能解决相应问题,则在该处理程序的最后,CPU 通过执行“异常/中断返回指令”回到被打断的用户进程的第 i 条指令或第 i+1 条指令继续执行。若异常或中断处理程序发现是不可恢复的知名错误,则中止用户进程。通常情况下,对于异常和中断事件的具体处理过程全部由操作系统(可能包括驱动程序)软件来完成。
异常的分类
intel 将内部异常分为三类
故障
故障是在引起故障的指令被启动后但未结束执行时 CPU 检测到的一类与指令执行相关的意外事件。这种意外事件有些可以回复,有些不能回复。如指令译码出现的非法操作码;取指令或者取数据时发生页故障,执行触发操作时发现除数为 0.
陷阱的重要作之一是在用户程序和内核之间提供一个像过程调用一样的接口,这个接口称为系统调用。操作系统给每个服务编一个号,称为系统调用号,每个服务功能通过一个对应的系统调用服务例程提供。如在 linux 中就提供了创建子线程(fork),读文件(read),加载并且运行新程序(execve)等服务功能。
用于程序调试的断点设置也是一种陷阱指令。
在 IA-32 中,陷阱指令引擎的异常称为编程异常,这些指令包括 INT n,int 3,into(溢出检查),bound(地址越界检查),通常将 INT n 称为软中断指令,该指令引起的异常通常也称为软中断。在 IA-32/Linux 中可以使用快速系统调用指令 sysenter 或者软中断指令 int $0x80 进行系统调用。
终止
如果在执行指令的过程中发生了严重错误,如控制器出现问题,访问 DRAM 或者 SRAM 时发生校验错误等,则程序无法继续执行,只好终止发生问题的进程。
中断的分类
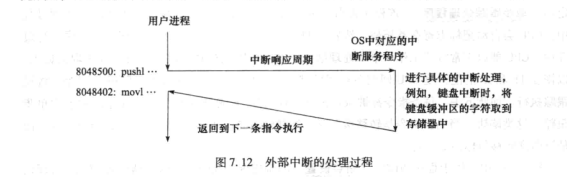
中断 是由外部 IO 设备请求处理器进行的一种信号。他不是由当前执行的指令引起的,外部 IO 设备通过特定的中断请求信号线向 CPU 提出中断申请。CPU 在执行指令过程中,每执行一条指令就查看中断请求引脚,如果中断请求引脚的信号有效,则进入中断响应周期。在中断响应周期中,CPU 先将当前 PC 值和当前机器状态保存到栈中,并设置成为关中断状态,然后从数据总线读取中断类型号,根据中断类型号跳转到对应的中断服务程序执行。中断响应过程由硬件完成,而中断服务程序执行具体的中断处理工作,中断处理完成后,再回到被打断程序的断点处继续执行。
可屏蔽中断
是指通过可屏蔽中断请求线INTR 向 CPU 进行请求的中断,主要来自 IO 设备的中断请求。CPU 可以通过在中断控制器中设置相应的屏蔽字来屏蔽他或者不屏蔽他。若一个 IO 设备的中断请求被屏蔽,他的中断请求信号不会被送到 CPU。
不可屏蔽中断
通常是非常紧急的硬件故障,通过专门的不可屏蔽中断请求线NMI 向 CPU 发出中断请求。
异常和中断的响应过程
CPU 从检测到异常或中断事件,到调出响应的异常或中断处理程序开始执行,整个过程称为异常和中断的响应。主要分为以下三个步骤: