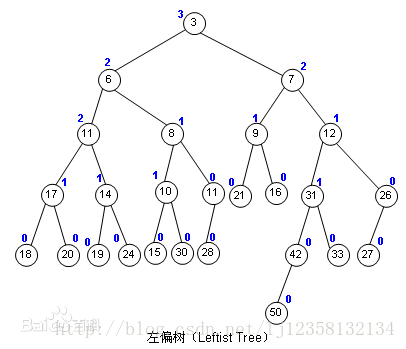
#include<bits/stdc++.h> usingnamespace std; constint maxn = 1e+7; int n; int p[maxn]; vector<int> gra[10]; vector<int> res; intinit(){ memset(p,0,sizeof(p)); for(int i = 1; i <= n; i++){ p[i] = i; } } intfind(int x){ return p[x]==x?x:p[x]=find(p[x]); } intunit(int x,int y){ p[x] = y; } voidaddedge(int x,int y){ gra[x].push_back(y); gra[y].push_back(x); } int s,e; int vis[maxn]; int path[maxn]; voiddfs(int x){ cout<<x<<endl; for(int i = 0; i < gra[x].size(); i++){ int to = gra[x][i]; if(!vis[to]){ path[to] = x;// 记录路径 vis[to] = 1; if(to == e){ return; } dfs(to); } } } intmain(){ freopen("in.txt","r",stdin); cin>>n; init(); memset(vis,0,sizeof(vis)); memset(path,0,sizeof(path)); for(int i = 0; i < n; i++){ int a,b; cin>>a>>b; int aa = find(a),bb = find(b); if(aa!=bb){ unit(a,b); }else{// 说明构成了环 s = a,e = b; break; } addedge(a,b); } vis[s] = 1; dfs(s); int temp = e; res.push_back(temp); while(path[temp]){ res.push_back(path[temp]); temp = path[temp]; } sort(res.begin(),res.end()); for(int i = 0; i < res.size(); i++){ if(i>0){ cout<<' '; } cout<<res[i]; } }
另外还可以采用深搜的方式,首先需要了解
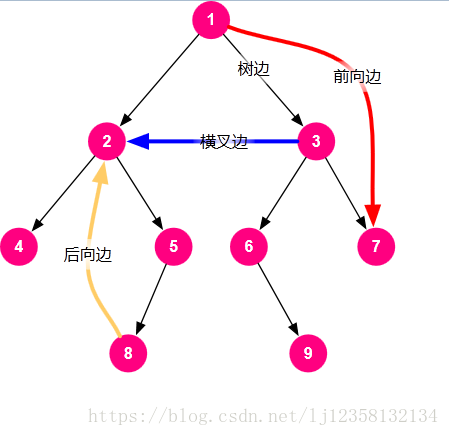
在图的遍历中,往往设置了一个标记数组 vis 来记录顶点是否被访问过。但有些时候需要改变 vis 值的意义。令 vis 具有 3 种值并表示 3 种不同含义
vis = 0,表示该顶点没没有被访问 vis = 1,表示该顶点已经被访问,但其子孙后代还没被访问完,也就没从该点返回 vis = 2,,表示该顶点已经被访问,其子孙后代也已经访问完,也已经从该顶点返回 可以 vis 的 3 种值表示的是一种顺序关系和时间关系
《算法导论》334 页有这 4 种边的准确定义
DFS 过程中,对于一条边 u->v vis[v] = 0,说明 v 还没被访问,v 是首次被发现,u->v 是一条树边 vis[v] = 1,说明 v 已经被访问,但其子孙后代还没有被访问完(正在访问中),而 u 又指向 v,说明 u 就是 v 的子孙后代,u->v 是一条后向边,因此后向边又称返祖边, vis[v] = 2,说明 v 已经被访问,其子孙后代也已经全部访问完,u->v 这条边可能是一条横叉边,或者前向边
注意:树边,后向边,前向边,都有祖先,后裔的关系,但横叉边没有,u->v 为横叉边,说明在这棵 DFS 树中,它们不是祖先后裔的关系它们可能是兄弟关系,堂兄弟关系,甚至更远的关系,如果是 dfs 森林的话,u 和 v 甚至可以在不同的树上
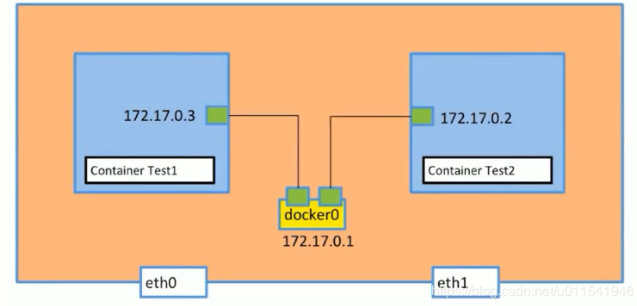
docker run -d --name=test2 --link test1 busybox /bin/sh -c "while true; do sleep 3600; done"
当于添加了 DNS 解析,同时 link 是单向的。只能在 test2 通过 test1 ping 通 test1。
none 和 host 网络
连接到 none 网络
1
docker run -d test1 --network none busybox /bin/sh
使用 none 模式,没有物理地址和 ip 地址,容器内只有 lo 回环网络,意味着容器不能被其他容器访问。
连接到 host 网络
1
docker run -d test1 --network host busybox /bin/sh
容器和外层 linux 共享一套网络接口
数据持久化 data volume
在 docker 中,默认数据存储在 container layer,也就是容器层中,因为只有这一层是可读可写的。但这样如果容器关闭了,并且被删除了,数据也就被删除了。docker 为了解决这种问题,出现一种机制。就是把数据转移到外挂或者 mount 的磁盘上。例如把容器里数据,同步到外层 linux 主机磁盘上。这样即使容器被删除了,容器里面数据还是保留在 linux 主机上,下次我们再启动一个容器,配置读取外层 linux 这个外挂的文件系统中数据,这个容器恢复正常服务功能。
VOLUME 的类型
有两种,第一种是受管理的 data Volume,由 docker 后台自动创建。第二种是绑定挂载的 Volume,具体挂载位置可以由用户指定。
安全防护与配置
Docker 是基于 Linux 操作系统实现的应用虚拟化。运行在容器内的进程,与运行在本地系统的进程在本质上没有区别。Docker 容器的安全性,很大程度上依赖于 Linux 系统自身。在评估 Linux 安全性上,主要考虑一下几个方面
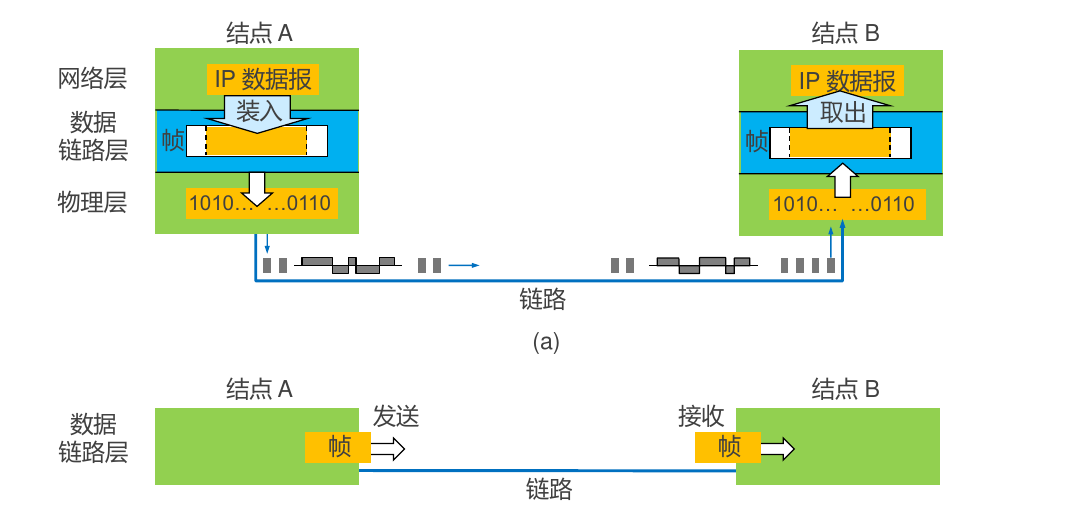
点对点通信在数据链路层的主要步骤 结点 A 的数据链路层把网络层交下来的 IP 数据报添加首部和尾部封装成帧
结点 A 把封装好的帧发给结点 B 的数据链路层 * 若结点 B 的数据链路层收到的帧无差错,则从收到的帧中提取出 IP 数据报交给上面的网络层,否则丢弃该帧 数据链路层不考虑物理层之间如何实现比特传输的细节
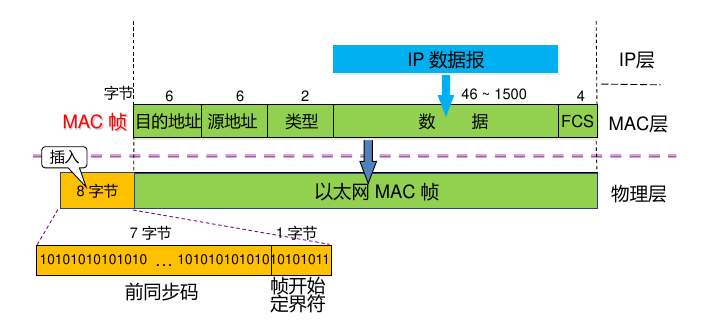
字符计数法 这种方法是在帧头部中使用一个字符计数字段来标明帧内字符数。例如,发送序列“5 A B C D E 4 U V W X 7 1 2 3 4 4 5 8”表示一共有三个帧,三个帧的长度分别为 5 字节、4 字节和 7 字节。但是这种方法很容易出现定界错误。假如计数值出现传输差错,接收端收到的序列为“5 A B C D E 6 U V W X 7 1 2 3 4 4 5 8”时,则接收端会将第二帧解释为“6 U V W X 7 1”,从而导致因发收双方对帧大小和内容理解不一致而出错。
带字符填充的首尾界符法 这种方法是在每一帧的开头加上 ASCII 字符“DLESTX” ,在帧末尾加上 ASCII 字符“DLE ETX” 。例如,假设待发送的数据是 ADLECB ,则在数据链路层封装的帧为:DLE STX ADLECB DLE ETX 如果发送方在数据帧中遇到帧头或者帧尾字符,就采用字符填充法来处理。例如,数据帧有 DLE 字符,就在其前面加一个 DLE。 DLE STX A DLE DLE CB DLE ETX
若得出的余数 R = 0,则判定这个帧没有差错,就接受(accept)。 若余数 R != 0,则判定这个帧有差错,就丢弃。但这种检测方法并不能确定究竟是哪一个或哪几个比特出现了差错。只要经过严格的挑选,并使用位数足够多的除数 P,那么出现检测不到的差错的概率就很小很小。
汉明码
汉明码(Hamming Code)编码的关键是使用多余的奇偶校验位来识别一位错误。假设信息码共有 n 位,海明码共有 h 位,那么总共的码长为 n + h 位。为能检测出 n + h 位编码,中其中一位的错误,海明码必须能够表示至少 n + h + 1 种状态,其中 n + h 种表示 n + h 位编码中有一位错误,另外还需要 1 种来表示整个编码正确无误。则海明码的长度需要满足下列关系:
PPP 协议的帧格式 标志字段 F = 0x7E (符号“0x”表示后面的字符是用十六进制表示。十六进制的 7E 的二进制表示是 01111110)。地址字段 A 只置为 0xFF。地址字段实际上并不起作用。控制字段 C 通常置为 0x03。PPP 是面向字节的,所有的 PPP 帧的长度都是整数字节。
var Assignment = mongoose.model("Assignment", { dueDate: Date }); Assignment.findOne(function (err, doc) { doc.dueDate.setMonth(3); doc.save(callback); // THIS DOES NOT SAVE YOUR CHANGE
doc.markModified("dueDate"); doc.save(callback); // works });
var Any = new Schema({ any: {} }); var Any = new Schema({ any: Object }); var Any = new Schema({ any: Schema.Types.Mixed });
ObjectIds
创造 SchemaTypes 或子文档数组。
1 2 3 4 5 6 7 8
var ToySchema = new Schema({ name: String }); var ToyBox = new Schema({ toys: [ToySchema], buffers: [Buffer], string: [String], numbers: [Number], // ... etc });
指定空数组相当于 Mixed
1 2 3 4
var Empty1 = new Schema({ any: [] }); var Empty2 = new Schema({ any: Array }); var Empty3 = new Schema({ any: [Schema.Types.Mixed] }); var Empty4 = new Schema({ any: [{}] });